[CM301] 02. 알고리즘의 분석
![[CM301] 02. 알고리즘의 분석](/CMajor/assets/img/thumbnails/cm301/2.png)
목표 세우기 - 올바른 알고리즘
정당성 (Correctness)
여러분은 어떤 문제를 풀기 위해 여러분만의 알고리즘을 만들었습니다. 과연 이 알고리즘은 제대로 굴러가는 걸까요? 여러분이 알고리즘을 알맞게 만들었는지 확인하려면, 아래 두 조건을 만족하는지 확인해야 합니다.
모든 입력값(instance)에 대해서 올바른 결과값을 내놓아야 하며
제 시간 안에 끝나야 한다.
만약 이를 모두 만족한다면 그 알고리즘은 정당하다(Correct)고 할 수 있습니다.
루프 (Loop)
앞으로 수많은 예시들을 살펴보며 알게되겠지만, 알고리즘에서 지루하고 똑같은 일을 처리하는 데에는 반복문(iteration)만큼 좋은 것이 없습니다. 반복문이 계속 돌면서 실행되는 구간을 루프(Loop)라고 하고, 꼭 알고리즘 공부가 아니더라도 코드에서 이 루프를 굉장히 자주 보게 될 거에요.
루프는 단순히 똑같은 작업을 반복할 수도 있지만, 반복마다 특정 조건이나 값이 달라지기도 합니다. 반면 반복마다 똑같이 유지되는 조건도 있을거에요. 루프 안에서 항상 참인 조건을 루프 불변량(Loop invariants)라고 합니다. 이 불변량은 알고리즘이 왜 정당한지 증명하는데 도움이 될 수 있는 중요한 요소입니다.
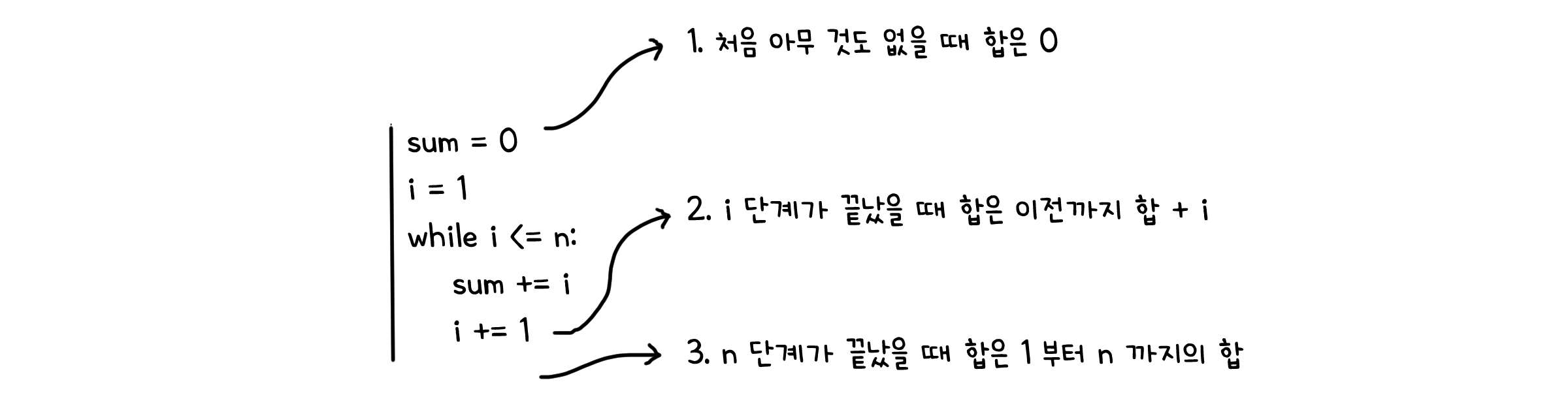
루프불변량은 크게 루프의 처음시점, 진행중, 그리고 종료시점 이 세가지 부분에서 참임을 보여야 성립합니다.
| 단계 | 시점 |
|---|---|
| 처음 (Initialization) | 루프가 처음 시작되기 전 |
| 중간 (Maintenance) | 루프의 한 반복이 끝났을 때 |
| 끝 (Termination) | 루프가 끝날 때 |
1
2
3
4
5
sum = 0
i = 1
while i <= n:
sum += i
i += 1
알고리즘의 복잡도
어떻게 해서 여러분은 방금 만들어낸 코드가 잘 작동하여 논리적 결함 없이 정당하다는 것을 증명해내었습니다. 이거면 충분할까요?

여유가 있다면, 우리는 이 알고리즘이 좋은 알고리즘인지도 따져볼 수 있겠습니다. 일반적으로 알고리즘이 좋고 나쁜지는, 알고리즘이 종료될 때 까지 걸리는 실행시간(Running time)을 기준으로 판단하게 됩니다.
점근적 해석(Asymptotic analysis)

맞아요! 실제로 알고리즘의 실행 시간을 측정하는 행위는 프로그램이 실행되는 컴퓨터 환경에 따라 달라질 수 밖에 없습니다. 때문에 우리는 컴퓨터 환경에 대한 영향을 완전히 배제하고, 순수히 알고리즘 상으로 걸리는 이론적 시간만을 고려할겁니다. 입력값을 아-주 크게 넣어줌으로서 해결할 수 있는데, 입력이 커질수록 컴퓨터 환경에 의한 차이보다 알고리즘 상의 차이가 실행시간에 영향을 더 많이 주게 되거든요. 입력값이 무한에 가까워졌을 때를 고려한다고 하여 이를 점근적 해석(Asymptotic analysis)이라고 합니다.
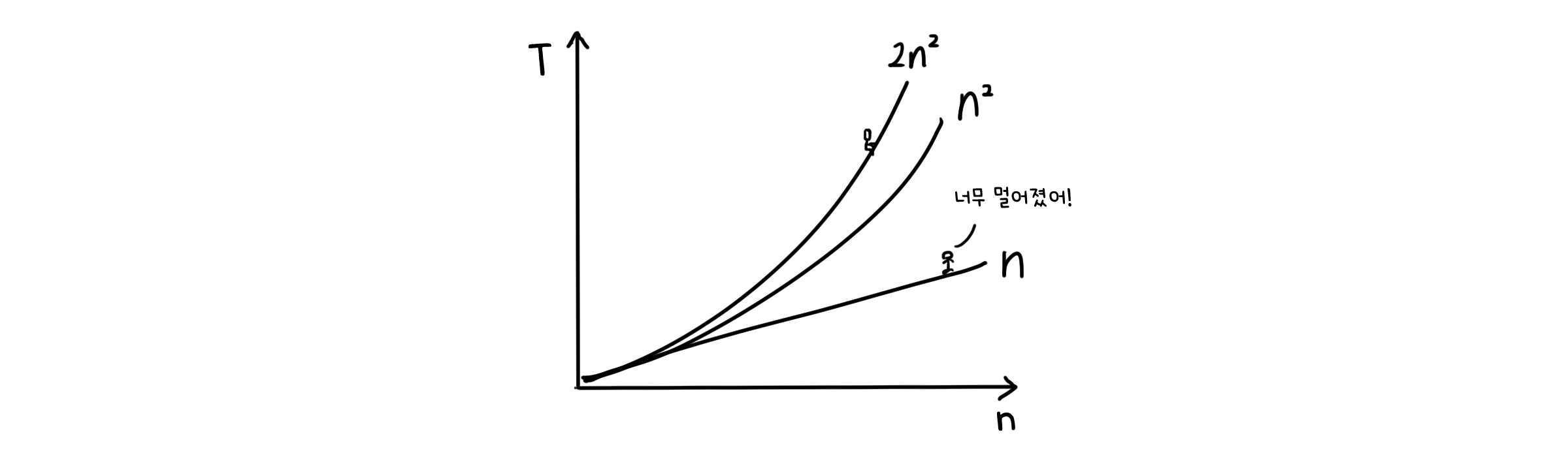
점근적 해석에는 또 다른 특징이 있는데, 실행시간을 가장 간단한 형태의 수식으로 나타낸다는 것입니다. 이것도 입력값이 무한에 가깝다는 가정으로부터 나오는데, 수식들을 입력값 크기에 대한 실행시간의 그래프로 그렸을 때 생기는 미세한 차이가 모두 무시될 수 있기 때문입니다. 예를 들어 입력 크기가 $n$일 때 실행시간이 $2^n$인 알고리즘과 $4n^2$인 알고리즘이 있다고 해봅시다. 처음엔 두 번째 알고리즘이 더 오래 걸립니다. 하지만 n이 8보다 커지면, 그때부터는 첫 번째 알고리즘이 더 오래 걸리기 시작합니다. 그 이후로는 대소가 역전될 일이 없고요. 이렇게 전체가 아니더라도 적당한 수 n 이상 부터 대소관계가 명확해지기만 하면 됩니다.
표기법 (Notation)
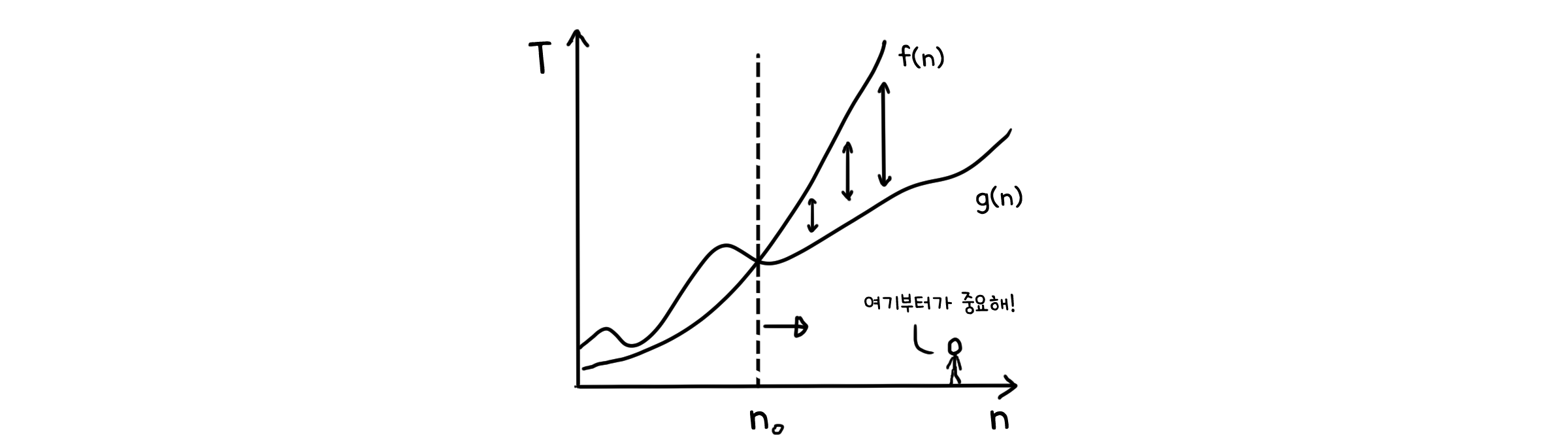
모든 알고리즘이 항상 같은 시간동안 실행되지는 않습니다. 입력값이 어떤지에 따라 실행시간이 짧을 수도, 혹은 길 수도 있죠. 그렇기 때문에 우리는 생각할 수 있는 가장 최악의 경우를 생각하게 됩니다. 최악의 수를 지표로 한다면 적어도 상상했던 것 보다 더 나쁜 일이 일어나지는 않을테니까요.

수식으로 표기할 때는 대문자 O를(0이 아닙니다!)사용해 $f(n) = O(n)$과 같은 식으로 표기하고, 이를 Big-O 표기법(BigOh Notation)이라고 합니다.

참고로, 아래는 Big-O 표기법 외에도 사용할 수 있는 표기법들과 그 정의입니다.
| 표기법 | 조건 | 정의 | $\lim_{n\to\infty}f/g$ |
|---|---|---|---|
| Theta ($\Theta$) | $f(n) \approx cg(n)$ | $\forall \; n \geq n_0 \quad \exists \; c_1, c_2, n_0 > 0 \quad 0 \leq c_1g(n) \leq f(n) \leq c_2g(n)$ | $\mathbb{R}^+$ |
| BigOh ($O$) | $f(n) \leq cg(n)$ | $\forall \; n \geq n_0 \quad \exists \; c, n_0 > 0 \quad 0 \leq f(n) \leq cg(n)$ | $\mathbb{R}^+ \; or \; 0$ |
| Omega ($\Omega$) | $f(n) \geq cg(n)$ | $\forall \; n \geq n_0 \quad \exists \; c, n_0 > 0 \quad 0 \leq cg(n) \leq f(n)$ | $\mathbb{R}^+ \; or \; \infty$ |
| LittleOh ($o$) | $f(n) < cg(n)$ | $\forall \; n \geq n_0, c > 0 \quad \exists \; c, n_0 > 0 \quad 0 \leq f(n) < cg(n)$ | $0$ |
| LittleOmega ($\omega$) | $f(n) > cg(n)$ | $\forall \; n \geq n_0, c > 0 \quad \exists \; c, n_0 > 0 \quad 0 \leq cg(n) < f(n)$ | $\infty$ |
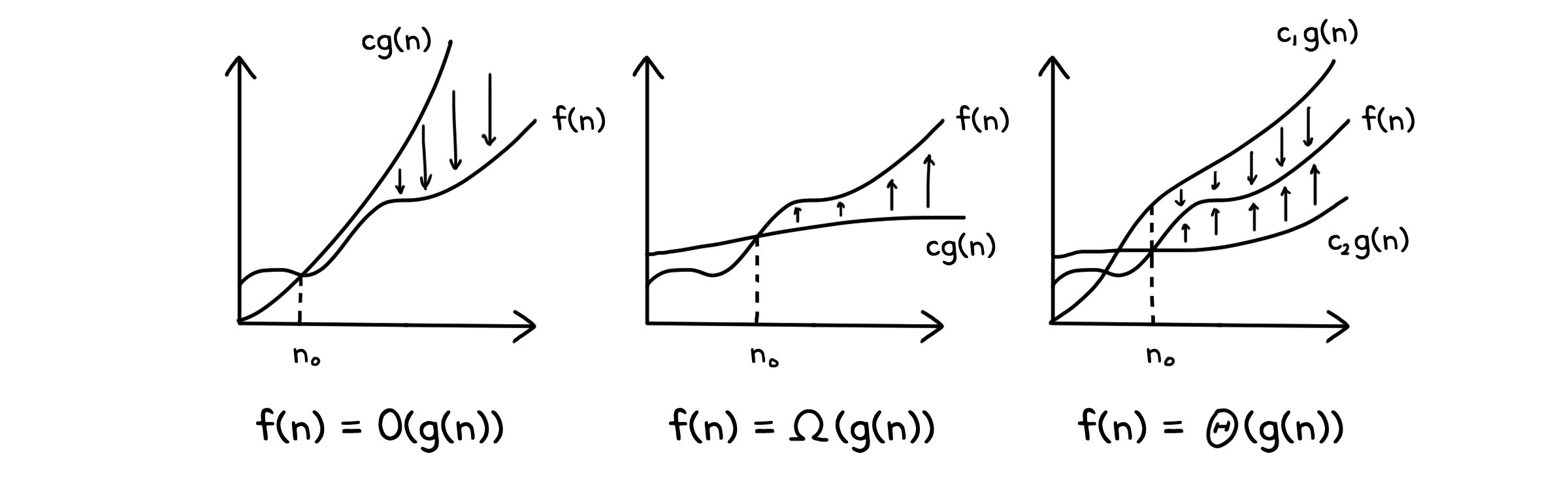
표에서 보이듯이 가장 정확한 측정 방식은 상한선과 하한선이 모두 명시된 $\Theta$표기법입니다. 하지만 실제로는 두 가지 경계를 모두 찾아야 하기 때문에 직접 계산하기에는 조금 번거로운 편입니다.
Theorem 1.
$f(n) = \Theta(g(n)) \; \leftrightarrow \; f(n) = O(g(n)) \; 이고 \; f(n) = \Omega(g(n))$
아래는 표기법들로부터 도출할 수 있는 몇 가지 성질들입니다.
Property 1.
$f \in O(g) \; \land \; g \in O(h) \; \rightarrow \; f \in O(h)$ ($\Theta$, $\Omega$, $o$, $\omega$에 대해서도 동일)
Property 2.
$f \in O(g) \; \leftrightarrow \; g \in \Omega(f), \quad f \in o(g) \; \leftrightarrow \; g \in \omega(f)$
Property 3.
$f \in \Theta(g) \; \leftrightarrow \; g \in \Theta(f)$
Property 4.
$\Theta$는 동치관계(Equivalence relation)이다.
Property 5.
$O(f+g) = O(max(f, g)), \quad \Omega(f+g) = \Omega(min(f , g))$
위와 같이 표기한 실행 시간을 시간복잡도(Time complexity)라고 부르기도 합니다. 실행시간이 길다는 것은 알고리즘이 처리하는 계산이 복잡하다는 뜻이기 때문입니다. 실행 시간 대신 알고리즘이 실행되는데에 사용하는 메모리를 표시한 것은 공간복잡도(Space complexity)라고 부릅니다. 컴퓨터는 한정된 메모리를 효율적으로 사용해야 하기에 공간 복잡도 또한 알고리즘 성능의 주요 고려사항입니다. 시간 복잡도가 낮은 대신 공간 복잡도가 높을 수도 있고, 시간 복잡도와 공간 복잡도가 모두 낮은 좋은 알고리즘도 있을 수 있습니다.
문제의 복잡도
이때까지 우리는 알고리즘이 얼마나 오래 걸리는지 그 복잡도에 대해 이야기해 보았습니다. 알고리즘의 시간 복잡도를 분석하는 이유는, 그 알고리즘이 얼마나 효율적으로 문제를 해결할 수 있는지를 알아보기 위함입니다. 하지만, 문제 자체가 굉장히 어렵고 복잡한 경우라면 어떻게 될까요? 아무리 좋은 성능의 알고리즘을 들고 와도 넘을 수 없는 벽이 있지 않을까요? 정말 알고리즘만으로 문제를 개선할 수 있는지 알기 위해, 우리는 문제 자체의 복잡도도 고려해야 합니다.

하한선 (Lower bound)
어떤 알고리즘 $A$에 대해 입력값 $X$를 넣었을 때 걸리는 시간을 $T_A(X)$라고 정의합시다. 그러면 크기 $n$인 입력값 중에서 제일 오래 걸리는 시간은 다음과 같이 나타낼 수 있습니다.
\[T_A(n) = \max_{|X| = n} \{T_A(X)\}\]이제 어떤 문제 $\Pi$를 생각해봅시다. $\Pi$를 풀 수 있는 알고리즘은 여러가지가 있을 수 있습니다. 그 중에서 최악의 경우에 대한 복잡도(Worst-case complexity)라고 하면 가장 빠른 알고리즘이 제일 오래 걸릴 때의 시간을 뜻합니다.
\[T_{\Pi}(n) = \min_{\Pi 를 풀 수 있는 A} \{T_A(n)\} = \min_{\Pi 를 풀 수 있는 A} \{\max_{|X| = n} \{T_A(X)\}\}\]즉, 이는 문제 $\Pi$에 대해 어떤 방법을 쓰더라도 최소한으로 걸리는 시간복잡도의 하한선(Lower bound)를 나타낸다고 볼 수 있습니다. 특정 값보다 작아질 수 없다는 맥락에서 우리는 $T_{\Pi}(n) = \Omega(f(n))$을 보임으로서 이를 증명할 수 있습니다.
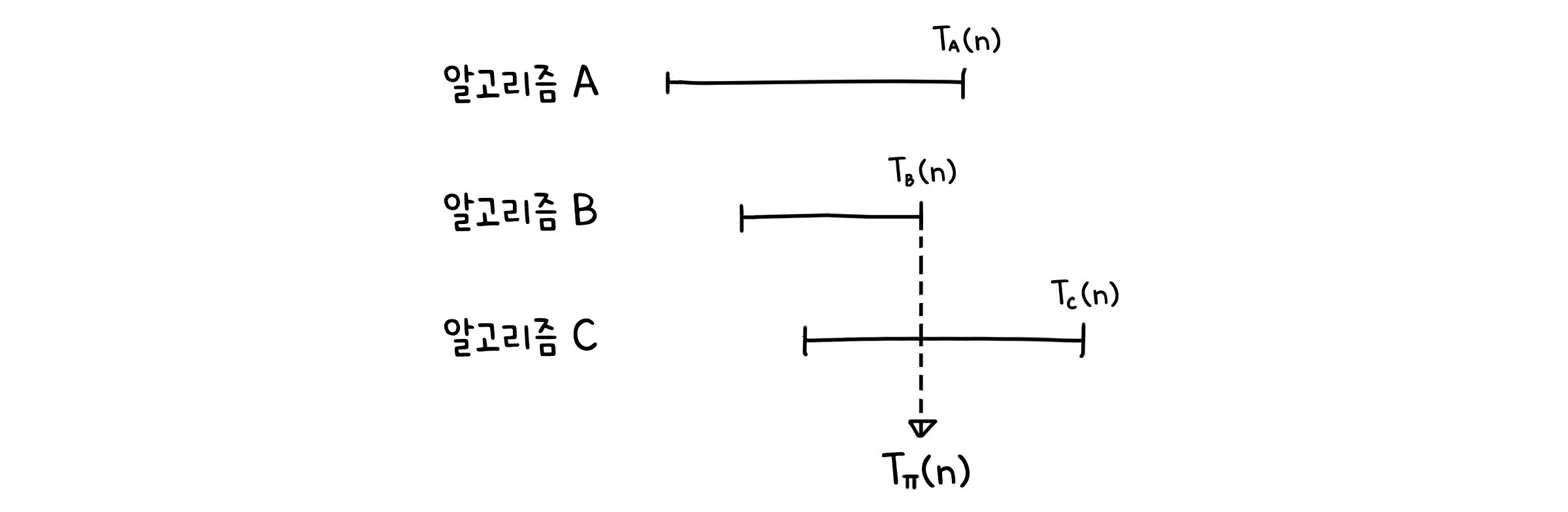
어디 까지를 계산으로 정의할까
문제의 하한선을 구하기 위해서 우리는 그 문제를 풀 수 있는 모든 알고리즘에 대해 시간 복잡도를 구해야 합니다(이론적으로요). 그러면 어디까지를 알고리즘이라고 칠 것인지, 어떻게 실행시간을 측정할 것인지 그 정의를 먼저 세워야 합니다. 이렇게 합의한 이론적 틀을 계산모델(Model of computation)이라고 합니다.
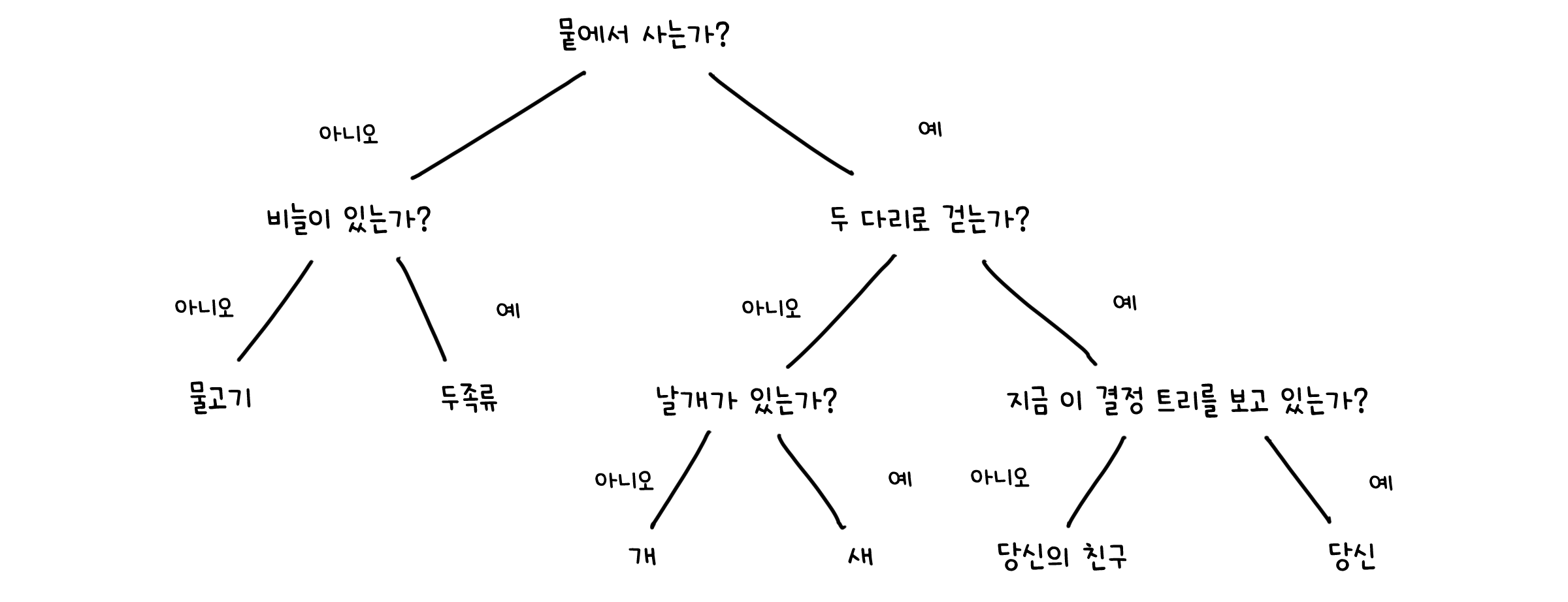
예시 - 의사 결정 트리 (Decision three model)
예시를 들어볼까요? 아직 다루지는 않았지만, 정렬 문제의 하한을 증명할 때는 어떤 계산 모델을 쓸 수 있는지 생각해봅시다. 정렬 문제는 주어진 배열의 요소들을 특정한 기준에 맞도록 재배열하는 것이 목표입니다. 여기서는 배열의 두 요소 x, y를 서로 비교하는 연산이 제일 중요한데요, 이것에 딱 맞는 계산모델이 의사 결정 트리 (Decision three model)입니다.
트리 구조는 그래프의 특별한 형태로, 더 자세한 내용은 이산구조에서 다루겠습니다.
의사 결정 트리는 트리 구조 중 하나로, 노드(Node)에는 입력값에 대한 질문(Query)을, 가지(Edge)에는 그 질문에 가능한 답변을, 그리고 잎(Leaf)에는 답변에 대한 출력값을 표시합니다.
앞서 말하였듯이 정렬은 비교 연산 만으로도 진행할 수 있습니다(데이터 입력이나 조건문 제어 같은 부차적인 것은 무시하도록 합시다). 따라서 의사 결정 트리를 사용할 때 노드를 ‘x < y인가?’라는 질문으로 사용할 수 있습니다. 가지는 ‘예’와 ‘아니오’ 두 가지가 나올 수 있고, 왼쪽 잎은 ‘예’에 대한 후속질문, 오른쪽 잎은 ‘아니오’에 대한 후속질문이 올 수 있겠죠. 모든 비교가 끝나고 마지막 말단 잎에는 정렬 결과가 나오게 하면 됩니다. 이렇게 하면 의사 결정 트리에서 지나오는 노드의 수를 알고리즘의 총 계산 수로 정의할 수 있습니다.
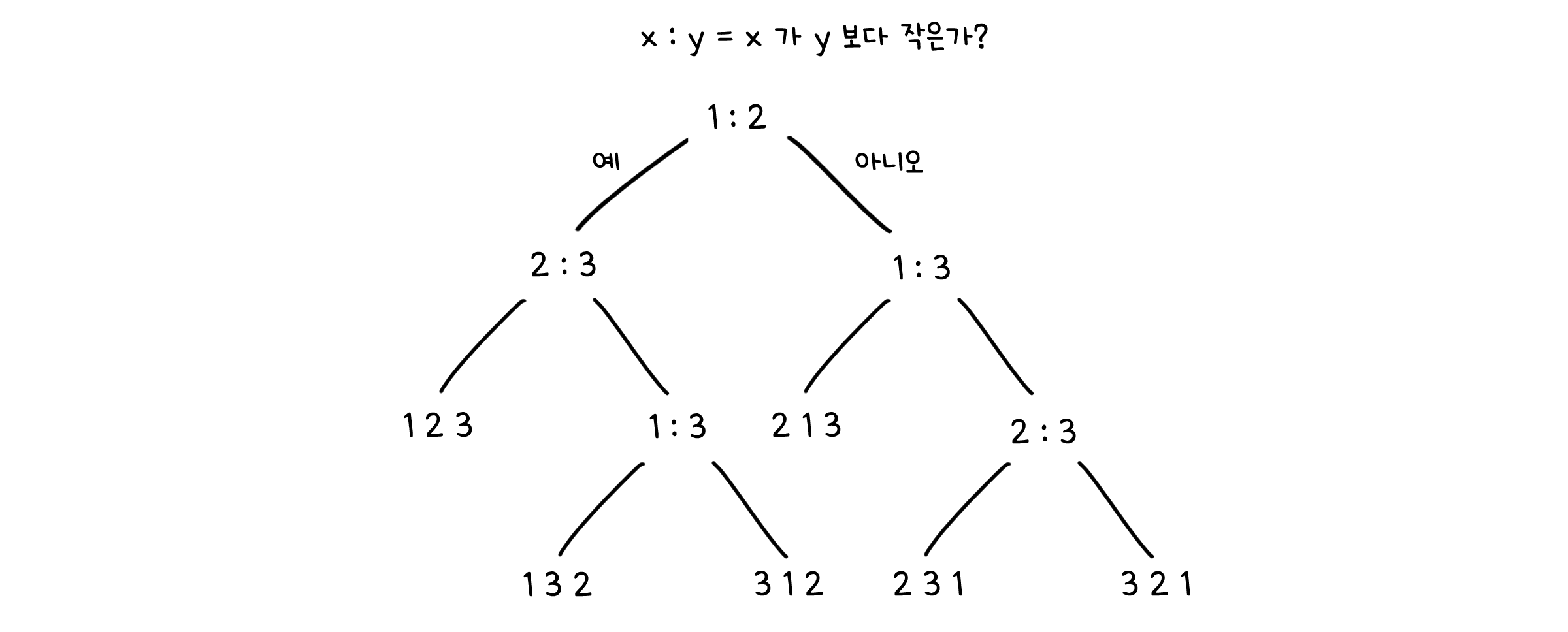
이제 우리는 의사 결정 트리의 정의에 근거하여 정렬 문제의 하한선을 구할 수 있습니다. 우선 입력값의 크기를 $n$, 트리의 높이를 $h$라고 합시다. 트리의 말단 잎들은 가능한 모든 경우를 포함해야 하기에, 최소한 n개의 요소를 정렬할 수 있는 경우의 수 $n!$ 만큼 존재해야 합니다.
\[n! \leq \text{잎의 수}\]한편으로는, 트리의 높이가 h이고 노드당 분화하는 가지의 수는 둘이기 때문에, 말단 잎의 개수는 $2^h$ 를 넘지 않을 것입니다.
\[\text{잎의 수} \leq 2^h\]따라서 이런 대소 관계가 성립합니다. 보기 좋게 로그도 취해줍시다.
\[n! \leq 2^h \quad \rightarrow \quad \log{n!} \leq h\]$\log{n!}$이 뭔가 복잡하죠. 대략적인 크기를 알아야 합니다. 스털링 근사(Stirling’s approximation)라는 기법으로 약간의 트릭을 사용하겠습니다.
\[n! = (\frac{n}{e})^n\sqrt{2\pi n}\]
이제 $\log{n!}$의 상한선과 하한선을 잡아줄 수 있습니다.
\[\log{n!} = \log{ \{\;(\frac{n}{e})^n\sqrt{2\pi n}\;\} } = n\log{(\frac{n}{e})} + \frac{1}{2}\log{2\pi n}\] \[= n(\log{n} - \log{e}) + \frac{1}{2}\log{2\pi n} = n\log{n} - n + O(\log{n}) = \Theta(n\log{n})\]따라서 트리의 높이 h, 즉 정렬에서의 계산량은 하한선 $n\log{n}$을 가지게 됩니다.
\[\log{n!} = \Theta(n\log{n}) \leq h \quad \rightarrow \quad h = \Omega(n\log{n}) \quad \Box\]힙 정렬, 병합 정렬, 퀵 정렬 등 대부분의 정렬 알고리즘은 모두 비교 연산만을 기반으로 합니다. 때문에 동일한 하한선을 가질 수 있어요. 하지만 특정 정렬 알고리즘은 비교 뿐만 아니라 덧셈과 같은 산술 연산 또한 사용하는 경우가 있어, 다른 모델에서는 복잡도가 달라질 수 있습니다. 핵심은, 모델이 다르면 하한도 달라진다는 것입니다.
어떤 문제의 상한선(Upper bound)이 존재한다는 건, 그 문제를 풀 수 있는 알고리즘이 존재한다는 뜻입니다. 상한은 특정 알고리즘이 있을 때만 정의되며, 다른 알고리즘이면 더 작은 상한이 나올 수도 있습니다. 하지만 하한선(Lower bound)은 알고리즘과 무관하게 이 문제를 푸는 데 필요한 최소 계산량으로 정의합니다. 즉, 문제의 이론적인 난이도를 뜻하는 것이죠.
알고리즘 분석이 중요한 이유
솔직히 일상에서 우리가 알고리즘의 속도차이를 체감하는 경우는 많지 않습니다. 하지만 여러분이 듣는 컴퓨터 과학에 대한 고학년 수업에서 과제를 복잡하게 만드는 악취미가 있으신 교수님이 있다면, 그 차이를 느낄 수 있을거에요. 실제 현업에서 다루는 프로그램은 더더욱 그럴테고요. 때문에 알고리즘의 성능을 분석하는 것은 여러가지 측면에서 모두에게 도움이 됩니다.
만약 알고리즘이 이상적인 실행시간을 가지고 있다고 판단되면, 이후 다른 프로그램을 작성할 때도 그 알고리즘을 사용할 수 있을겁니다.
문제상황이 더 커지면 얼마나 시간이 걸릴지 미리 예측할 수 있습니다.
현재의 알고리즘이 이상적이지 않아도 상관 없습니다. 알고리즘을 분석하는 활동 자체가 알고리즘을 개선할 기회를 줄 수도 있습니다.
알고리즘의 성능을 분석하면서 그 활동 기작에 대해 더 잘 이해할 수도 있고요.
알고리즘이 얼마나 ‘어려운지(hard)’ 알 수도 있지만, 이 이야기는 잠시 미뤄둡시다…
