[CM202] 06. 리스트 (List)
![[CM202] 06. 리스트 (List)](/CMajor/assets/img/thumbnails/cm202/6.png)
스택과 큐는 특별한 입출력 순서가 제약되어 있는 자료형이었습니다. 이제 조금 더 일반적인 형태의 자료형을 다뤄볼까요? 우리에게 가장 친숙한 개념인 리스트에 대해 살펴봅시다.
리스트 (List)
리스트(List)는 순서가 있는 원소들의 모임입니다. 순서가 있기 때문에 인덱스가 존재하고, 이를 통해 ‘n번째 원소’와 같이 특정 위치의 원소에 바로 접근할 수 있습니다.

비슷하긴 한데, 다릅니다. 리스트는 추상적인 자료형이고, 배열은 그것을 구현할 수 있는 데이터 구조거든요. 따지자면 리스트를 구현할 수 있는 데이터 구조 중 하나가 배열이 되는 것이죠.
리스트의 특징을 보면 스택이나 큐와는 달리 특별한 입출력 조건이 없습니다. 값을 넣을 때 아무 위치에나 넣을 수 있으며, 뺄 때도 마찬가지 입니다. 이전의 두 ADT보다 더 일반화된 형태라고 볼 수 있죠.
ADT: List
리스트도 값을 추가(add)하거나 제거(remove)하는 기능을 포함해야 합니다. 또한 값을 수정하지 않았던 스택이나 큐와는 달리, 특정 위치의 요소 값을 가져오거나(get) 수정하는 것(set)도 고려해야 합니다.
1
2
3
4
5
6
7
8
public interface List<E> {
int size(); // 스택의 크기 반환
boolean isEmpty(); // 비어 있는지 여부 반환
E get(int i); // 요소 가져오기
E set(int i, E e); // 요소 수정
void add(int i, E e); // 요소 추가
E remove(int i); // 요소 제거
}
데이터 구조: ArrayList
리스트의 특징이 영락없이 배열과 닮아 있으니, 아무래도 배열을 통해 구현해보는게 맞겠죠. 배열a 의 i번째 메모리 a[i]가 리스트의 i번째 요소를 저장하도록 만들면 되겠습니다. 이렇게 한다면 get( )과 set( )함수는 배열의 인덱스 접근을 사용하기만 하면 되니까요.
ArrayList - 멤버
| 이름 | 자료형 | 기본값 | 기능 |
|---|---|---|---|
| data | E[] | - | 배열 |
| size | int | 0 | 크기 |
| CAPACITY | int | 16 | 전체 용량 |
ArrayList - 메소드
| 이름 | 매개변수 | 반환값 | 기능 |
|---|---|---|---|
| size() | - | int | 길이 반환 |
| isEmpty() | - | boolean | 비어 있는지 여부 |
| get(int i) | i : 인덱스 | E | 요소 가져오기 |
| set(int i, E e) | i : 인덱스, e : 값 | E | 요소 수정 (이전 값을 반환) |
| add(int i, E e) | i : 인덱스, e : 값 | - | 요소 추가 |
| remove(int i) | i : 인덱스 | E | 요소 제거 |
메소드 살펴보기
checkIndex( )
우선, 리스트 공간을 벗어나는 인덱스 접근을 방지하기 위해 올바른 접근을 하는지 확인하는 함수를 구현해야 합니다. i 번째 요소에 접근한다고 할 때, i는 0에서 size-1까지의 값을 가져야 합니다. 그러므로 그 외의 i값이 올 경우에는 예외처리를 해주면 됩니다.
1
2
3
4
5
protected void checkIndex(int i, int n) throws IndexOutOfBoundsException {
if (i < 0 || i >= n) {
throw new IndexOutOfBoundsException("Illegal index: " + i);
}
}
get( )
1
2
3
4
public E get(int i) throws IndexOutOfBoundsException {
checkIndex(i, size);
return data[i]; // 인덱스를 통한 접근
}
set( )
1
2
3
4
5
6
public E set(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i]; // 반환할 값 저장
data[i] = e; // 인덱스를 통한 접근
return temp;
}
add( )
1
2
3
4
5
6
7
8
9
10
11
public void add(int i, E e) throws IndexOutOfBoundsException, IllegalStateException {
checkIndex(i, size + 1);
if (size == data.length) { // 만약 배열의 크기를 벗어난다면
throw new IllegalStateException("Array is full"); // 예외 처리
}
for (int k=size-1; k>=i; k--) { // i번째 이후의 값들은
data[k+1] = data[k]; // 한 칸씩 다음으로 이동
}
data[i] = e; // i번째 자리에 값 추가
size++; // 크기 한 칸 증가
}
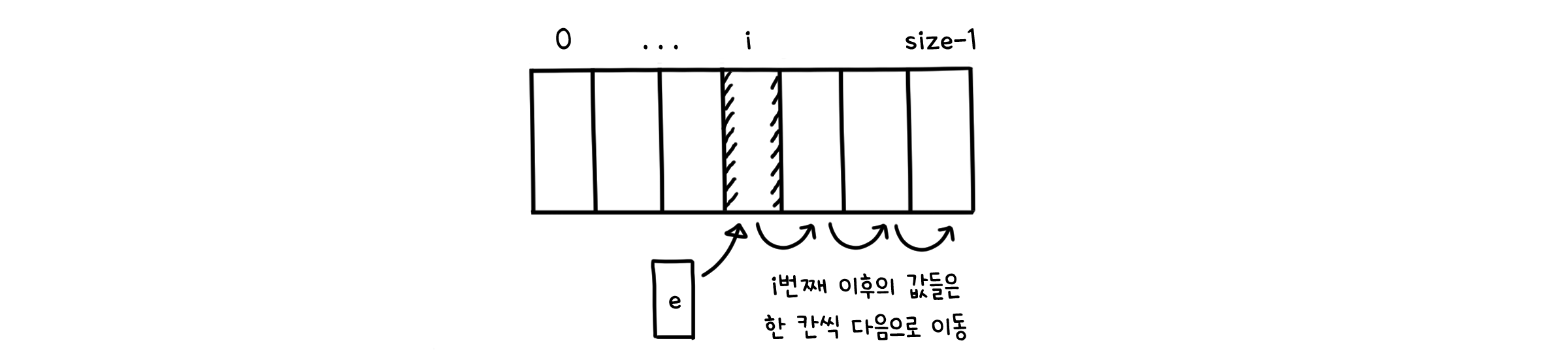
remove( )
1
2
3
4
5
6
7
8
9
10
11
public void remove(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i]; // 반환갈 값 저장
for (int k=i; k<size-1; k++) { // i번째 이후의 값들은
data[k] = data[k+1]; // 한 칸씩 이전으로 이동
}
data[size-1] = null; // 맨 끝 자리는 비움
size--; // 크기 한 칸 감소
return temp;
}
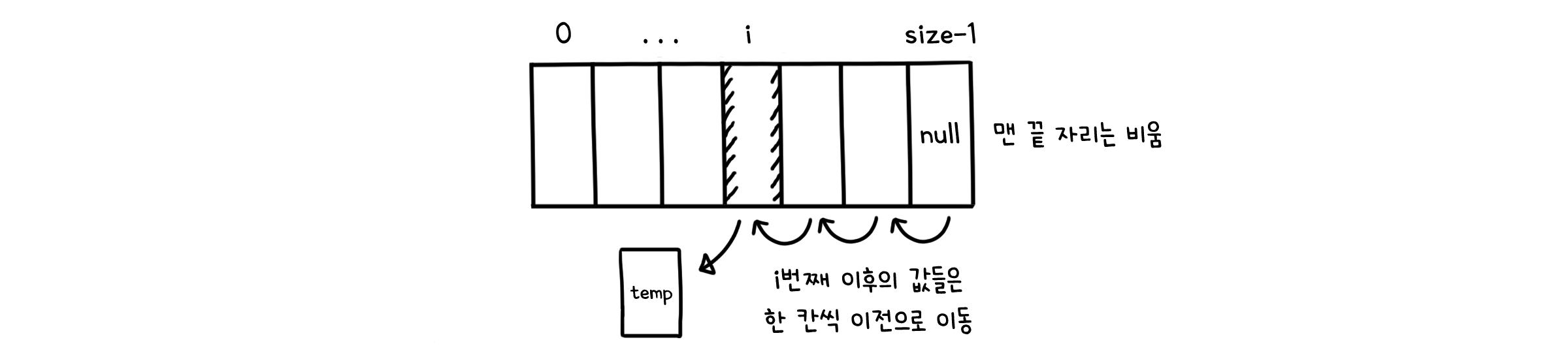
배열의 크기 바꾸기
배열을 이용해 만든 리스트는 배열의 문제점을 그대로 가져갑니다.

네, 맞아요. 정해진 배열의 크기를 넘어서면 요소를 추가할 수 없게 됩니다. 그렇다고 배열 크기를 처음부터 무작정 크게 잡으면 공간 낭비가 될 것이 뻔합니다. 그러니 요소를 추가하거나 제거할 때마다 배열의 크기를 동적으로 바꿀 수 있는 방법을 생각해야겠습니다.
크기 바꾸기 - resize( )
기본적인 아이디어는 배열의 크기가 부족할 때 더 큰 크기의 배열을 만든 뒤, 기존 배열의 값들을 복사해오는 것입니다. 3장에서 언급했듯이, 배열은 특정 주소를 가리키기 때문에 복사할 때는 직접 순회하며 각 요소들을 하나씩 옮겨주어야 합니다.
1
2
3
4
5
6
7
8
protected void resize(int capacity) {
E[] temp = (E[]) new Object[capacity]; // capacity 크기의 배열을 새로 선언
for (int k=0; k<size; k++) { // 기존 배열의 모든 요소를
temp[k] = data[k]; // 새로운 배열의 같은 인덱스에 복사
}
data = temp; // 기존 배열이 새로운 배열을 가리키도록 함
}
Java는 제네릭 타입의 배열을 바로 선언할 수 없기 때문에 E[ ] 타입의 배열을 선언할 때
new E[capacity]라고 쓸 수 없습니다. 대신 임의의 Object 타입의 배열을 만든 뒤, E[ ] 타입으로 다시 캐스팅하는 방법을 사용해야 합니다.
크기 늘리기 - 두 배 전략 (Doubling strategy)
그렇다면 우리는 resize()를 실행할 때마다 배열을 얼마나 크게 만들어야 할까요? 가장 간단한 방법은, 무조건 두 배의 크기를 잡는 것입니다. 그러니까 만약 요소를 추가할 때 자리가 없다면, 현재 배열 크기의 두 배 길이만큼 크기를 늘리는 것이죠.
1
2
3
4
5
6
7
8
9
10
11
public void add(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size + 1);
if (size == data.length) {
resize(2 * data.length); // 예외 처리 대신 resize()를 실행합니다.
}
for (int k=size-1; k>=i; k--) {
data[k+1] = data[k];
}
data[i] = e;
size++;
}
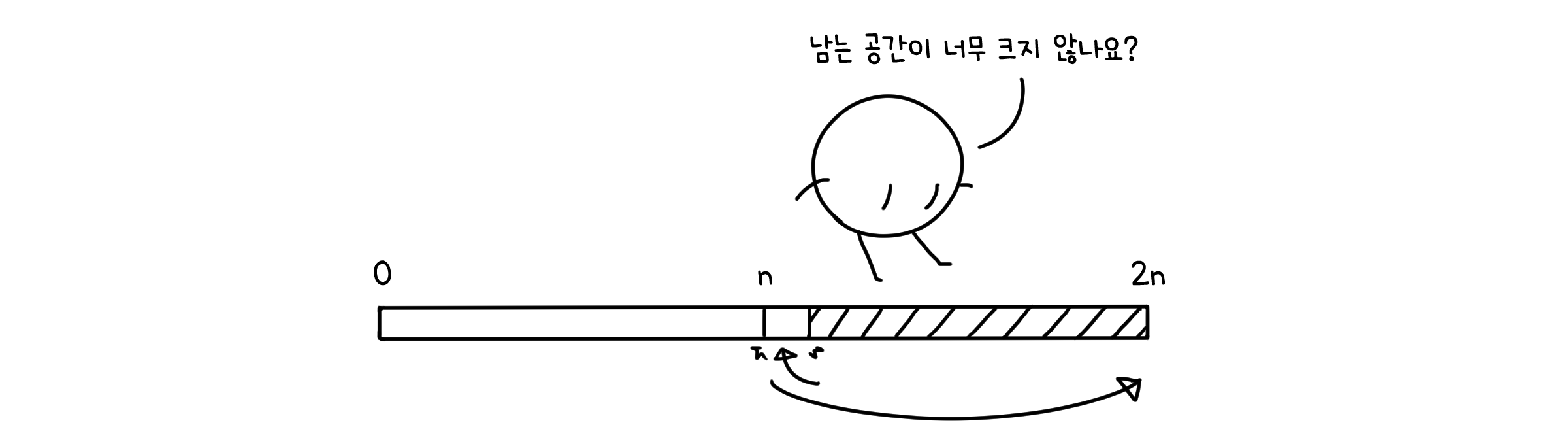
실제로 계속 두 배로 커진다면 그 크기 엄청나게 커질거에요. 하지만 resize( )는 배열이 가득 찼을 때만 늘어납니다. 때문에 배열이 커질수록 복사 이벤트는 더 드물게 일어나 크게 신경 쓰지 않아도 될겁니다.
수식으로 좀 더 자세히 볼까요? 우리가 n개의 값을 배열에 차례대로 넣는다고 해봅시다. 여기서 $n = 2^k$이고요. 위 코드에서 알 수 있듯 resize()를 한 번 실행할 때 배열의 길이 만큼 연산을 하게 됩니다(하나씩 복사하니까요). 그렇다면 n개 값을 맨 끝에 추가할 때 총 연산의 수는 이렇게 됩니다.
\[n + 1 + 2 + 4 + \; ... \; + 2^k\] \[= n + 2^{k+1} - 1\] \[= n + 2 * n - 1\] \[= 3n - 1\]즉, 총 실행시간은 $O(n)$이 되고, 요소 하나를 넣는데 걸리는 실행시간은 $O(1)$이 됩니다. 실행하는데에는 큰 문제가 되지 않는다는 것이죠.
O(n)은 알고리즘의 실행시간을 나타내는 표기법 중 하나로, 최대 n만큼의 시간이 걸리다는 의미입니다. 실행시간에 대한 더 자세한 내용은 알고리즘에서 다루겠습니다.
크기 줄이기 - 절반 전략 (Halving strategy)
반대로 배열의 절반 이상이 빈 공간이라면, 현재 배열 크기의 절반 길이만큼 크기를 줄일 수도 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public void remove(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i];
for (int k=i; k<size-1; k++) {
data[k] = data[k+1];
}
data[size-1] = null;
size--;
if (size>0 && size == data.length / 4) { // 크기가 1/4 이하라면
resize(data.length / 2); // 배열의 크기를 절반 합니다.
}
return temp;
}
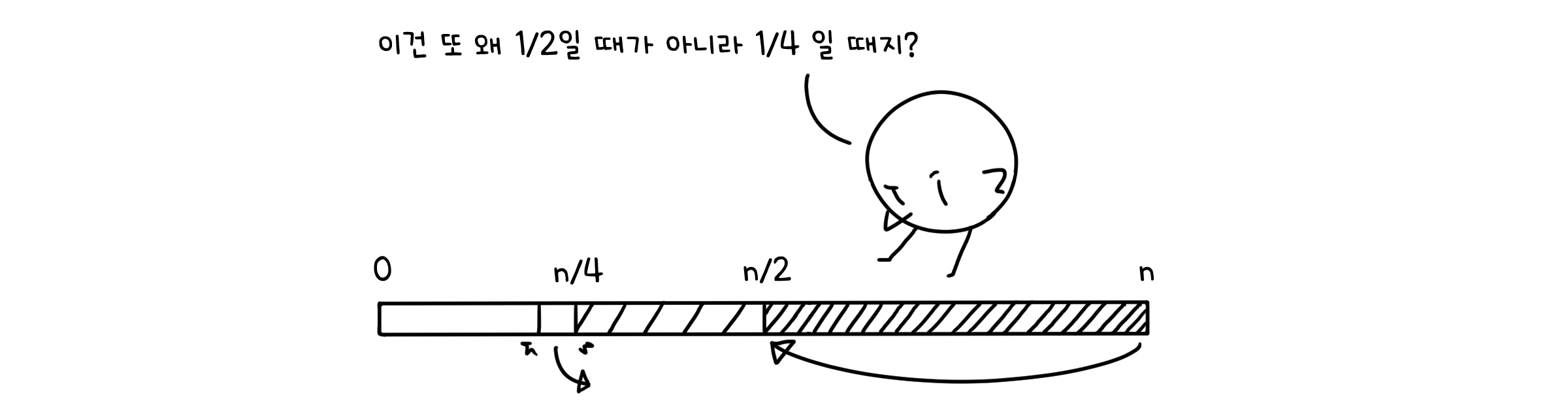
두 배로 늘어날 때와는 달리 절반으로 줄어드는 것은 갈수록 그 크기가 작아집니다. 그래서 절반 크기를 기준으로 체크하면 길이 축소가 잦아질 수 있어요. 그래서 넉넉하게 1/4 정도로 기준을 잡은 것입니다.
반복자 (Iterator)
앞서 여러 메소드들을 살펴보았을 때, ‘순회한다’라는 개념이 상당히 중요하다는 것을 알 수 있습니다. 당장 배열 연산만 해도 for 반복문을 써서 값들을 한 칸씩 옮겼으니까요. 이렇게 데이터 구조 안의 모든 원소를 차례대로 방문하는 기능은 반 필수적으로 구현해야 하는 요소입니다. 이 기능을 반복(iteration)이라고 하고, 반복을 수행하는 객체를 반복자(iterator)라고 합니다.
반복자는 다음 요소가 있는지 반환하는 hasNext() 메소드와 다음 요소를 반환하는 next() 메소드를 필수적으로 가지고 있어야 합니다. 이 두 가지 메소드를 가진 객체가 반복자(Iterator)이고, 이 반복자를 반환할 수 있는 객체를 반복 가능한 객체 (Iterable)라고 부릅니다.
1
2
3
4
5
6
7
8
9
10
// java에서 반복자 Iterable<E>는 java.lang.Iterable 에 미리 구현되어 있습니다.
public Interface Iterator<E>{
boolean hasNext(); // 현재 요소에서 다음 요소가 있는지 반환
E next(); // 현재 요소의 다음 요소를 반환
}
public interface Iterable<E> {
Iterator<E> iterator(); // 반복자를 반환하는 메소드
}
우리가 정의한 ArrayList 또한 반복자가 필요한데, ArrayIterator라는 이름의 내부 클래스로 구현해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private class ArrayIterator implements Iterator<E> {
private int j = 0; // 현재 위치 표시용
public boolean hasNext() {
return j < size; // 현재 위치가 최대 길이보다 작은지
}
public E next() {
if (!hasNext()) { // 만약 다음이 없다면
throw new NoSuchElementException(); // 예외처리
}
return data[j++]; // 아니면 인덱스 접근 후 위치 한 칸 이동
}
}
4장에서 구현했던
Node클래스와는 달리 정적(static) 클래스로 선언되지 않았습니다. 그 이유는 ArrayIterator 클래스가 외부 값인 size와 data를 참조하고 있기 때문입니다. 정적 클래스는 외부 인스턴스의 참조가 없는 경우에만 선언할 수 있습니다. 간단히 생각해서 같은 클래스의 모든 인스턴스가 똑같은 함수를 쓸 수 있으면 그 함수는 정적인 것이라고 생각하면 됩니다.
이제 우리는 ArrayList의 반복자를 반환할 수 있는 iterator() 메소드를 만들 수 있습니다.
1
2
3
public Iterator<E> iterator() {
return new ArrayIterator();
}
어떤 데이터 구조던 반복자를 제공한다면, 우리는 내부 구조를 몰라도 같은 방식으로 순회를 할 수 있습니다. 가령 데이터 안의 모든 요소를 차례대로 순회하기 위해 for 문을 사용한다면, 내부적으로는 반복자가 아래와 같이 실행되는 방식이죠.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Iterator<String> iter1 = arrayList.iterator(); // 배열을 사용하던
Iterator<String> iter2 = linkedList.iterator(); // 연결 리스트를 사용하던
// 이 두 개의 코드는
while(iter1.hasNext()) {
System.out.println(iter1.next());
}
while(iter2.hasNext()) {
System.out.println(iter2.next());
}
// for 문과 같은 효과가 있습니다.
for(String s: arrayList)
System.out.println(s);
for(String s: linkedList)
System.out.println(s);
전체 코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
// interface: Iterator
public interface Iterator<E> {
boolean hasNext();
E next();
}
// interface: Iterable
public interface Iterable<E> {
Iterator<E> iterator();
}
// interface: List
public interface List<E> {
int size();
boolean isEmpty();
E get(int i);
E set(int i, E e);
void add(int i, E e);
E remove(int i);
}
public class ArrayList<E> implements List<E>, Iterable<E> {
// nested class: ArrayIterator
private class ArrayIterator implements Iterator<E> {
// member
private int j;
// constructor
private ArrayIterator() {
j = 0;
}
// methods
public boolean hasNext() {
return j < size;
}
public E next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
return data[j++];
}
}
// member
public static final int CAPACITY = 16;
private E[] data;
private int size;
// constructor
public ArrayList() { this(CAPACITY); }
public ArrayList(int capacity) {
data = (E[]) new Object[capacity];
size = 0;
}
// methods
public int size() { return size }
public boolean isEmpty() { return size == 0 }
public E get(int i) throws IndexOutOfBoundsException {
checkIndex(i, size);
return data[i];
}
public E set(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i];
data[i] = e;
return temp;
}
public void add(int i, E e) throws IndexOutOfBoundsException, IllegalStateException {
checkIndex(i, size + 1);
if (size == data.length) {
resize(2 * data.length);
}
for (int k=size-1; k>=i; k--) {
data[k+1] = data[k];
}
data[i] = e;
size++;
}
public void remove(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i];
for (int k=i; k<size-1; k++) {
data[k] = data[k+1];
}
data[size-1] = null;
size--;
if (size>0 && size == data.length / 4) {
resize(data.length / 2);
}
return temp;
}
// utility functions
protected void checkIndex(int i, int n) throws IndexOutOfBoundsException {
if (i < 0 || i >= n) {
throw new IndexOutOfBoundsException("Illegal index: " + i);
}
}
protected void resize(int capacity) {
E[] temp = (E[]) new Object[capacity];
for (int k=0; k<size; k++) {
temp[k] = data[k];
}
data = temp;
}
public Iterator<E> iterator() {
return new ArrayIterator();
}
}